跨模态哈希检索技术由于存储量低和检索速度快的优点,广泛应用于多媒体检索相关的应用中。由于不同模态数据存在异构性,在有限长度的哈希编码中编码不同模态的相似度信息依旧是跨模态哈希检索的主要挑战。尽管基于深度学习的跨模态哈希检索方法已经取得巨大进展,但是依然存在以下问题:(1)二进制哈希码的长度很短,通常小于128位,大多数有意义的信息被丢弃,导致哈希码无法准确度量跨模态数据的语义一致性。而实值检索方法则可以充分利用高维特征中所包含的丰富信息,弥补多模态数据的异质性问题。因此,可以利用高维特征来引导二值哈希码的学习,从而消除多模态数据的语义鸿沟。(2)有限长度的哈希码容易受到跨模态不一致信息(图文描述不一致)的干扰,严重降低检索性能。在实际的检索应用中,原始图像/文本之间的跨模态语义不一致的情况是很难处理的。因此,增强跨模态相关信息和过滤无关信息是非常重要的。(3)目前跨模态数据集中的样本都具备多个类别标签的标注信息,与单标签标注相比,可以在更细粒度的级别上度量语义相关性。此外,多标签标注为多模态数据提供了更多的语义信息,可以进一步用于消除跨模态数据的异构差异。基于以上讨论,我们设计了如图1所示基于多层次关联对抗哈希(MLCAH)的跨模态检索模型。MLCAH模型包含三个多模态数据分支,即ImgNet、LabNet和TxtNet。根据功能的不同,ImgNet和TxtNet可以进一步划分为特征学习模块、注意力模块和哈希模块;LabNet可以划分为特征学习模块和哈希模块。三个模块的具体内容如下:(1)特征学习模块使用卷积神经网络或多尺度融合模型提取全局特征表示;(2)注意力模块生成自适应注意力掩膜,并将全局特征划分为相关特征和无关特征:(3)哈希模块主要是将全局信息、标签信息和局部信息合并,生成多模态数据的最终语义表示,并进行二值化和多标签预测。为了进行多层次语义关联,模型设计了两种语义对齐机制,分别是全局语义对齐机制和局部语义对齐机制。在全局语义对齐中,利用各模态精心设计的特征学习模块和哈希模块,学习模态特有的高维全局特征及其对应的哈希码。同时,LabNet学习语义标签表示,并监督全局特征和哈希码的学习,最大限度提高跨模态的语义相关性。在局部语义对齐中,采用对抗训练的标签一致性注意力机制来获取跨模态局部相关信息,并将原始的全局特征转化为相关和不相关的语义特征。最后,将全局特征和局部相关特征串接在一起,输入到一个简单的全连接层中,得到融合特征并生成对应的哈希码,用于最终的检索任务。MLCAH模型在四个跨模态检索数据集都取得了较好的性能。相关研究成果发表在TMM 2020。
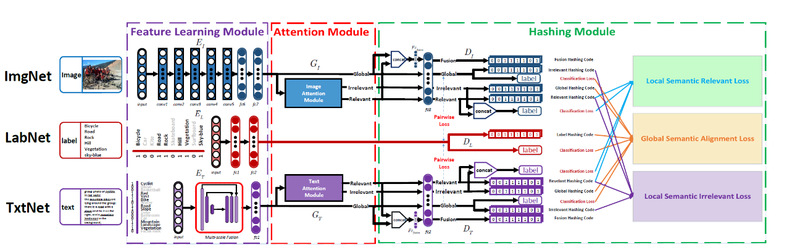
图1. 基于多层次关联对抗哈希(MLCAH)的跨模态检索模型