赋予机器感知人类情绪的能力,使得机器可以准确识别人的情感状态,进而对其做出合适的反应,是真正实现人机交互的重要目标之一。然而,目前人脸表情数据库中的情感图像由于人物姿态多变、背景复杂、表情变化微弱、类内差异大、数据量较小等原因,很难训练得到鲁棒的人脸表情识别模型。针对上述问题,现有人脸表情识别方法通常包括三个阶段:(1)人脸检测与预处理:检测人脸相关区域,进行人脸对齐;(2)表情相关特征提取与表示:提取具有判别性的情感特征;(3)表情识别:训练情感分类模型。针对以上三个步骤,目前已有大量相关研究成果被提出,并被应用于多个领域,但由于人脸表情的复杂性,使得自动人脸表情识别技术仍然具有较大挑战,存在较多技术难点,且现有方法通常针对某一阶段展开研究,但上述三个步骤通常是紧密相关且可以相互促进的。为了解决该问题,我们通过一个端到端的模型对人脸图像生成、人脸关键点检测以及表情识别三个紧密相关的任务进行同时建模,使得三种任务可以相互约束、相互促进,很好地解决了三个任务中存在的问题。具体的,如图1所示,所提方法利用生成对抗网络生成不同姿态和不同表情下的人脸图像,用其解决目前带标签人脸数据不足的问题。利用人脸关键点检测得到有效的几何信息,该几何信息在人脸图像合成任务中可作为几何约束加入生成对抗网络,也可作为几何特征与图像空间特征相结合,提高表情识别率。利用表情识别任务可向人脸图像生成和人脸关键点检测提供训练指导,进一步提升所生成的人脸图像的有效性以及检测到的人脸关键特征点的准确性。在3个公开人脸表情数据集上的实验结果表明所提方法具有较好的效果。研究成果发表在国际期刊IEEE TIP 2020上。
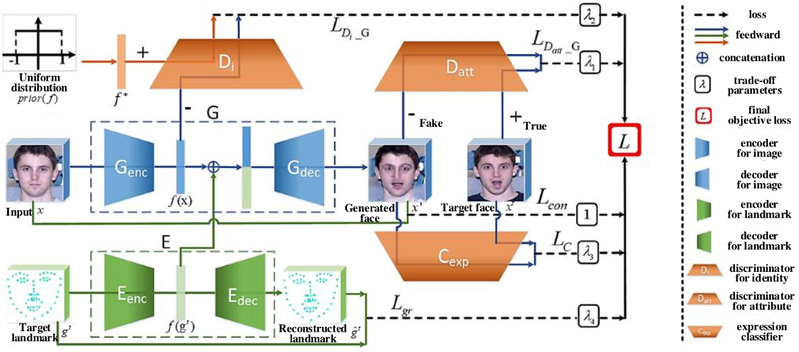
图1. 基于多任务协同分析的鲁棒人脸表情识别方法