随着社交网络与在线视频平台的兴起,网络上每天都在涌现大量的视频,伴随着这些视频而来的是与日俱增的行为类别。虽然有监督的行为分类方法取得了显著的进展和很好的效果,但是这些方法依赖于大量的标注样本,而标注这些数据是极为耗时耗力的。因此,零样本视频分类的方法应运而生。目前,通过自动挖掘潜在概念(如行为、属性等)进行零样本视频分类的方法获得了极大的成功。但是,大多数现有方法只利用了视频的视觉信息而忽视了对这些概念之间的显式关系建模。因此,我们提出了一个基于知识图谱的端到端零样本行为识别框架,如图1所示,其可以联合建模行为-属性、属性-属性、行为-行为之间的关系。具体的,我们设计了一个双支图卷积神经网络,其包括一个分类器支和一个实例支。分类器支输入所有概念的词向量并产生对应概念的分类器。实例支将属性的词向量和和每个视频实例的属性得分映射到一个特征空间中。最后,学习到的分类器在产生的属性特征上进行评估,并通过一个分类损失进行端到端地整体优化。为了考虑视频的时序建模,我们还引入了一个自注意力模型来有效利用视频的时序信息。在3个行为识别数据集上的实验结果表明提出方法具有很好的效果。研究成果发表在国际会议AAAI 2019上。
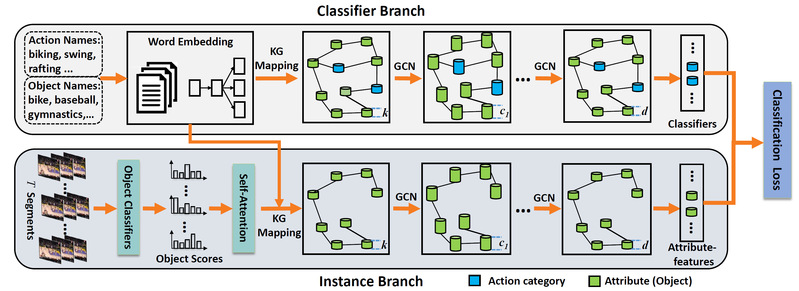
图1. 基于双支图网络的零样本行为识别方法