行人重识别是一个重要的计算机视觉任务,其在安防监控等领域具有重要的应用价值与研究意义。行人是一个非刚体结构,其姿态、视角变化会造成的不同摄像头下行人外观巨大的差异,这些外观上的差异是影响识别精度的主要因素之一。此外,深度学习虽然在有监督的行人重识别方法中取得了重大的进展,但也极大地增大了对标注数据的需求,大规模人工标注行人重识别数据代价极大,而小数据集训练的模型泛化能力不够理想。针对上述问题,本文提出了一个有效的行人重识别框架,如图1所示。首先,通过一个GAN模型生成不同姿态下的行人图像,为了更好的生成目标姿态的行人图像,本文在GAN的基础上引入一个姿态估计器用以在训练过程中指导生成目标姿态。其次,本文用原训练数据以及生成数据分别训练两个Resnet网络,由于生成数据会有信息损失,因此在使用这些数据时采用了标签平滑技术(LSR)。测试阶段,两个网络分别从原图像及其对应的20张生成的任意姿态下的行人图像提取特征,然后进行融合,使得最终得到的特征对姿态变化具有很强的鲁棒性。同时,由于生成了大量的任意姿态下的行人数据,整个模型的可扩展性与泛化性能都有很大的提升。研究成果发表在国际顶级会议ACM MM2018上。
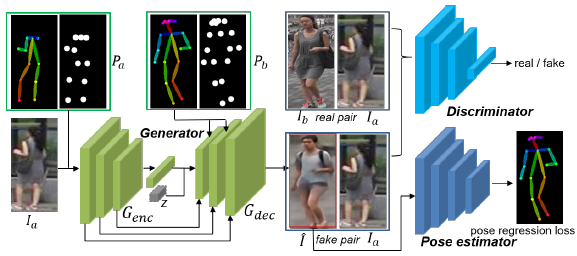
图1. 基于生成对抗网络的图像生成与行人重识别方法