语音识别将语音内容转换为对应文字序列,对于中文语音识别任务来说,则将语音转换为汉字序列。汉字由笔画的有序空间排列组成,笔画的一部分组合形成语音成分,为整个汉字的发音提供线索,其他笔画组合形成语义成分,指示语音上下文的语义信息。 为了探索汉字的内部笔画与语音之间的关联性,课题组提出了一个利用象形文字的表音性和表意性信息的端到端语音模型Speech2Stroke,通过Speech2Stroke直接从语音生成笔画。
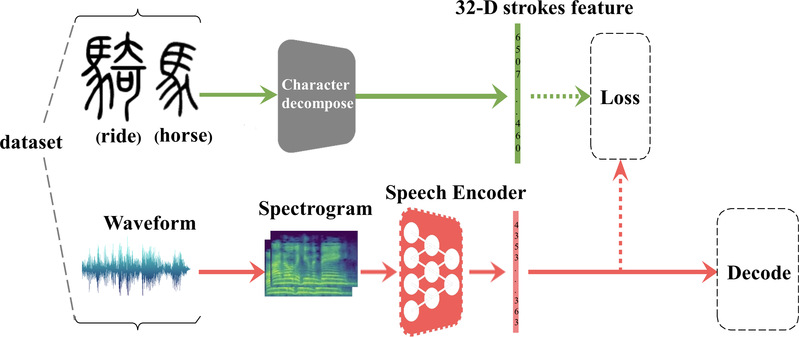
图1. Speech2Stroke模型的整体架构
图1为课题组提出的模型,主要包括:(1)收集相关的数据集,本文涉及一个特殊的笔画结构信息数据集,这个数据集是本文研究的基石;(2)语音特征的表示学习,设计可以学习到语音表示特征的神经网络,其输入为手工提取后的语音特征,输出标签为笔画序列;(3)文字的降解,先将词降解为字,然后将单个文字进行结构降解成32维度的笔画序列,以表示文字的结构信息;(4)端到端的模型训练,应用前向-后向算法优化CTC损失函数来进行端到端的训练,模型结构类似DeepSpeech2,如图2所示;(5)序列解码,对神经网络最后一层softmax的输出进行解码操作,以最终得到笔画序列。

图2. 语音编码器结构
课题组在录音时长约178小时的中文普通话数据集AISHELL-1上验证模型的性能。分别对贪心解码和集束搜索解码两种解码方式进行对比实验,不同解码方式模型的SER表现如表1所示。
表1 不同解码方式模型的SER

为了更加形象地展示解码效果,将测试集中的一条音频数据输入模型后采用集束搜索解码,由于解码出的笔画序列无法直观地看出效果,解码的笔画序列再经过人工反向翻译成汉字,其效果图如图3所示,可以看出,对比拼音和字,笔画模型的关联优势在于不需要额外的语言模型就可以确定一个字,这也显示出结构信息的优势,笔画相比字级别有更多的结构信息,不容易产生模糊不清的现象,表明汉字内在结构的确因为形声字的存在可以映射到语音上。

图3. 音频数据解码效果图