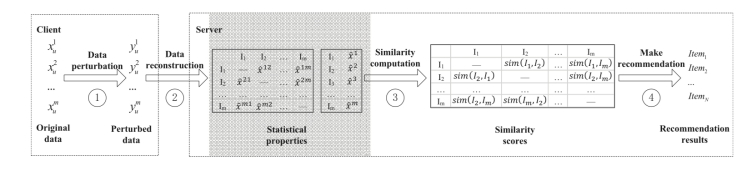
近年来,基于项目的协同过滤引起了广泛的关注。它根据用户报告的历史数据(即他们已经感兴趣的项目)向用户推荐他们可能感兴趣的新项目。在推荐服务不完全可信的情况下,所报告的历史数据会导致重大的隐私风险。在对个人隐私保护机制的研究中,有很多针对个人隐私保护机制的研究。然而,这些机制大多不能保证建议的准确性。这一问题的主要原因是这些方法直接从扰动数据中计算相似性。因此,计算的相似性总是不准确的,这种不准确的相似性最终导致不准确的推荐结果。本文提出了一个基于局部差异私有项的协同过滤框架,在用户端保护用户的私有历史数据,而在服务器端重构相似度以保证推荐的准确性。通过估计两个项目中没有一个或两个都没有评分的用户数量,重建了每一对项目的相似性。最后的推荐是由重构的相似性生成的。实验结果表明,我们提出的方法在推荐精度和隐私性与准确性之间的权衡方面明显优于现有的方法。
本研究由东南大学在本项目的资助下主导完成,成果发表在CCF B类期刊Information Sciences上,全文可访问https://doi.org/10.1016/j.ins.2019.06.021。