近年来,基于传感器信号和第一视角视频数据的多模态行为识别研究引起了广泛的关注。相比传统的基于传感器信号或视频数据的行为识别方法,多模态行为识别能利用多个模态数据之间的互补特性,进一步提升行为识别性能。然而,以个体为中心的多模态行为数据具有数据采集周期长、标注困难等特点,造成了目前可用的标注样本少的问题,难以依靠数据驱动的深度学习模型进行有效的多模态特征融合。为了在少量样本的条件下,有效地融合多模态行为数据,我们提出了一种知识驱动的多模态第一视角行为识别框架,其包含语义特征提取模块、实体关系构建模块和知识驱动的特征融合与识别模块,如图1所示。具体地,语义特征提取模块包含两个单模态的初始行为预测器和目标物体提取器。初始行为预测器分别基于传感器的运动特征和第一视角视频的视觉特征计算初始的行为预测分数,目标提取器从视频数据中计算得目标物体的估计分数。之后利用外部语义知识,将所有概念的估计分数嵌入到对应的语义特征中。实体关系构建模块基于数据中提取的实体概念,结合外部知识图谱构建概念之间的关系图。知识驱动的特征融合模块包含一个用于多模态特征融合的双支图卷积LSTM 网络,知识驱动的行为识别模块为一个用于分类器学习的图卷神经网络。特征融合模块和行为识别模块利用图神经网络协同建模行为和物体之间的关系,最终实现了知识驱动的行为识别。在3个多模态第一视角行为识别数据集上的实验结果表明提出方法具有很好的效果。研究成果发表在国际期刊ACM TOMM 2020上。
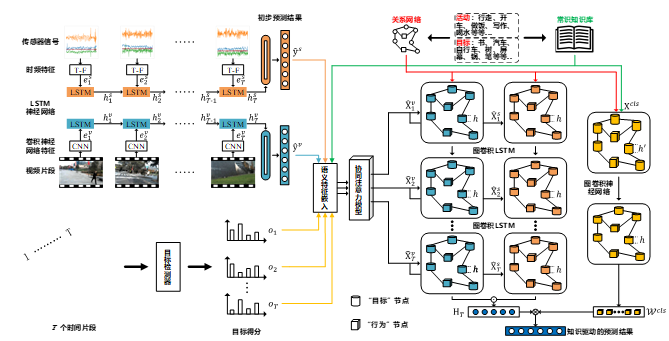
图1. 知识驱动的多模态第一视角行为识别方法