随着便携摄像机和智能眼镜等可穿戴设备的普及,人们可以通过视频记录自己的生活。但是,在各种时间、地点,以不同的目的上传的原始视频,大多数时间长度差异很大(短则几分钟,长则几小时)且充满噪声。浏览那些既冗长又没有固定结构的视频会浪费大量的时间而且枯燥无味,因此如何自动选出视频中的关键部分(重要或是特别有趣的片段)即视频精彩片段检测任务成为解决这个问题的关键。现有基于监督学习的方法存在样本数量不足,标记耗费人力物力大的问题。现有无监督学习检测视频精彩片段的方法没有显式地利用全局语义信息。视频精彩片段检测本质上是一个硬赋值的任务,它是一个离散的过程,不可微,很难使用梯度反传梯度反向传播等方法优化。我们利用无监督学习的方法,减少对大量标记数据的需求,用图神经网络刻画帧之间的依赖关系,如图1所示。对视频的中的帧赋予“关键片段”或“非关键片段”的标签。并使用“关键片段”与“非关键片段”与原视频特征的差异作为损失函数,优化硬赋值模块,得到视频最终的关键片段。研究成果发表在IEEE T-MM上 2020。
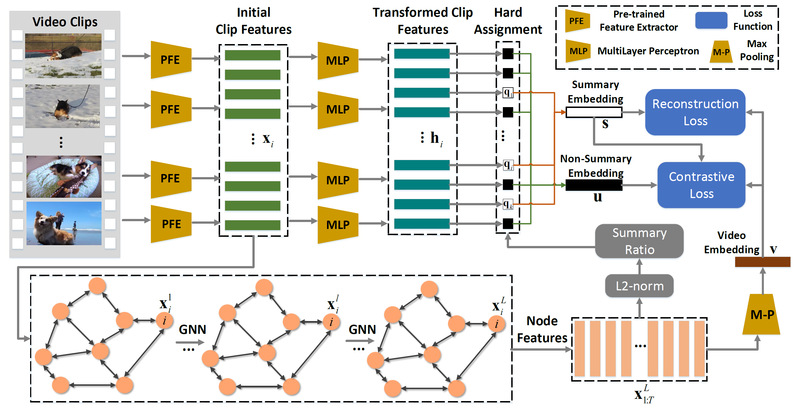
图1. 基于关系指派学习的无监督视频摘要方法