近年来,人脸表情识别研究已经取得了很大发展,但是任意姿态的人脸表情识别仍然存在很大挑战。现阶段任意姿态人脸表情识别系统主要包括三类:(1)为每种人脸姿态分别建立对应的表情识别模型;(2)忽略姿态因素,为不同姿态的所有人脸图像建立单一的表情识别模型;(3)通过建立不同姿态间映射关系进行姿态归一化,为不同姿态的人脸表情图像建立统一的表情识别模型。第一种多分类器方式需要根据姿态的不同训练众多模型,且需要为每个模型单独调节参数。第二种单一分类器无法去除姿态的干扰信息也必然会影响到最终模型的识别率。第三种统一分类器多是通过定位人脸关键特征点学习非正脸图像与正脸图像映射关系的方法,然后提取对姿态具有鲁棒性的特征,从而使任意姿态的人脸表情识别任务可以在一个统一的模型中完成,这很大程度依赖于关键特征点定位的准确性,尤其是侧脸状态下的关键特征点定位目前仍然存在很大困难。为了解决上述问题,我们提出一种基于生成对抗网络的方式,对姿态以及表情进行联合建模,同时完成任意姿态、表情的人脸图像合成以及人脸表情识别任务,如图1所示。具体的,采用基于几何条件的生成对抗网络合成任意姿态和任意表情下的带标签人脸图像,得到充足的带标签人脸表情训练样本。然后借助深度神经网络强大的非线性拟合能力应对由于表情类内差异大而导致的情感识别率低的问题,提高了最终人脸表情识别率,实现任意姿态人脸表情识别任务。在3个公开人脸表情数据集上的实验结果表明所提方法具有较好的效果。研究成果发表在国际期刊IEEE TIP 2020上。
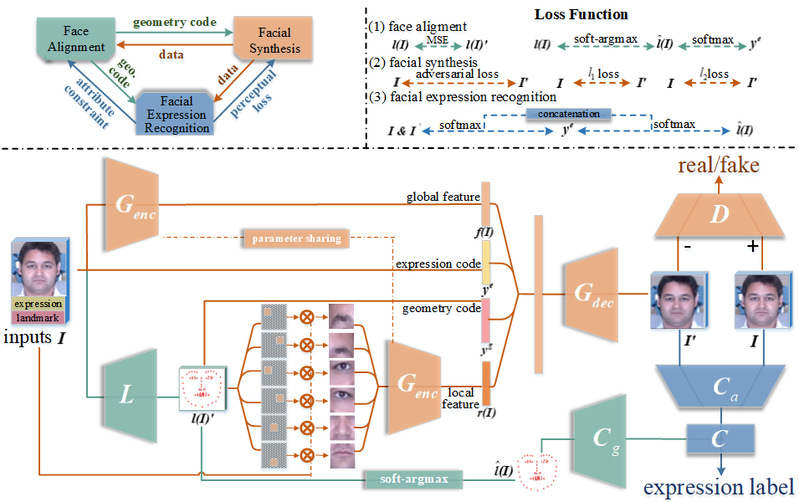
图1.基于连续几何约束的任意姿态人脸表情识别方法