在联邦学习过程中,当全局模型出现大量预测错误时,有效定位训练数据中的错误有着重要的研究和应用价值。由于联邦学习过程中参与用户本地的数据和模型参数作为用户隐私对服务器和其他用户不可见,对错误数据的检测和筛选成为十分具有挑战性的课题。针对该问题,课题组提出了保护数据隐私且高效的检测联邦学习用户本地训练数据中的错误数据的机制,并提出了以较小代价来修复数据错误以提升联邦学习系统性能的方法。项目组首先从理论上分析了现有中心化错误数据检测方法应用在联邦学习场景会由于庞大的计算和通信开销导致方法不可行;进而提出了基于模型训练日志的有错误数据的用户检测方法,以及基于影响函数的错误数据检测方法;接着,在理论分析的基础上设计了一个基于层次化影响力分析的错误用户和数据检测方法,以及模型性能提升方法。项目组搭建了一整套包含50个节点的AIoT系统,在真实系统和模拟的大型联邦学习场景验证了所提出的方法,有效、低开销地检测出用户本地的错误数据,使模型性能得到了很大的提升,细节如图1所示。
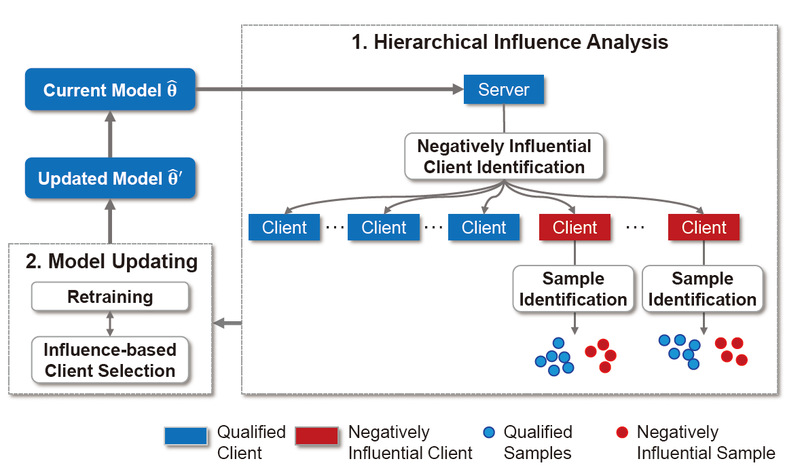
图1. 联邦学习场景中分层次高效错误数据检测机制
在联邦学习过程中,用户本地的低质量数据(例如,错误标签数据,类别确实的数据,非均匀分布的数据等)将严重阻碍全局模型取得良好的效果。由于本地数据是用户隐私,如何从用户数据中挑选高质量的数据参与训练是一项困难的任务。课题组系统地分析了训练数据质量对联邦学习模型效果的影响,提出了一种在给定预算下,以一种隐私保护的方式为给定的联邦学习任务选择一组高质量的训练样本,从而提高模型的精度和加快模型收敛速度的方法。给定一个联邦学习任务,首先利用PSI技术选择和该任务相关的用户和数据,然后基于同质性用户选择和多样性用户选择准则从相关用户集中选择高质量用户集。为了进一步改善模型性能并减少训练开销,在每轮训练迭代中选择一定比例的用户,同时用户在本地基于重要性采样选择对训练影响力大的数据样本参与模型训练。细节如图2所示,以上研究成果被CCF推荐A类会议IEEE ICDE 2021和IEEE INFOCOM 2021接收,并申请相关发明专利两项。
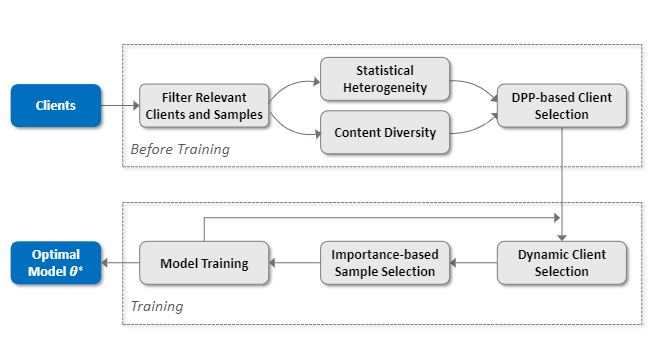
图10. 联邦学习场景中高质量数据选择机制